计算机最早是只有英文ASCII码,但世界上除了英语,还有很多其他语言,因此只有ASCII码编码显然不适合这种情况。
于是后来在中国、日本等其他国家都有了自己的一套编码,但是这样就出现问题了,不同国家之间数据传输,就会出现乱码。
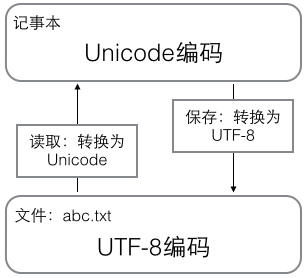
为了让全世界都可以使用计算机,于是有了Unicode编码方式,俗称万国码,可以存储好几万个字符。(unicode专题TODO)
因此计算机内存中,对字符串的编码使用的都是Unicode,作为中间者。
但是又有新的问题出现了,Unicode是定长编码,不适合存储,非常浪费存储空间,这里又有了一种新的编码方式:utf-8。utf-8采用的是不定长编码,大大节约了存储空间。在数据存储和传输方面非常方便。
当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码(或者其他编码)。


pyhton2 中的编码过程
1 | # _*_ coding:utf8 _*_ |
在运行前,python解释器默认以ASCII码解码文件,因此如果文件中有中文就会报错:
Non-ASCII character '\xe9',表示出现了超出ASCII码(0-127)以外的字节,因此需要在文件第一行添加:# _*_ coding:utf8 _*_,让编译器以指定的字符集进行解码然后编译。在运行时,Python2 中字符串有2种类型:
<type 'str'>和<type 'unicode'>,默认是str类型 。变量s的类型是<type 'str'>,可以理解为保存了“中文”以utf8编码的二进制数据。s.encode('utf8')命令实际上过程是这样的:1
2
3
4s.decode(defaultencoding).encode('utf8')
# 类型的转变过程
<type 'str'> ——以defaultencoding解码——> <type 'unicode'> ——以encode方法指定的字符集编码——> <type 'str'>1
2import sys
print(sys.getdefaultencoding()) # asciidefaultencoding在python2中默认是ASCII,而s是以utf8编码的,因此在str—>unicode的时候就会出现UnicodeDecodeError解决办法有2种:
显式进行解码
s.decode('utf8').encode('utf8')修改系统默认字符集
1
2
3
4
5import sys
reload(sys)# Python2.5初始化后会删除sys.setdefaultencoding这个方法,因此需要重新载入
print(sys.getdefaultencoding()) # ascii
sys.setdefaultencoding('utf-8')
print(sys.getdefaultencoding()) # utf-8
u前缀
在python2里面,u表示unicode string,类型是unicode, 没有u表示byte string,类型是 str。
1 | s1 = '中文' # '\xe4\xb8\xad\xe6\x96\x87' |
字符串长度问题
1 | # python2.7 |
Python3 中的编码过程
1 | s1 = '中文' # '中文' |
python3的改进:
Python3在编译时,文件默认就是以
utf-8进行解码然后编译python3中所有字符串都是以unicode格式(\uXXXX)保存在内存中,
u前缀没有特殊含义了。只有<class str>类型,对应的就是python2中的<type 'unicode'>。而<class byte>类似于python2的<type 'str'>。encode函数根据参数指定的编码方式,把str类型的字符串转换为bytes类型。而在python3中字符串没有decode函数,byte类型才有。在python3中,我们将不能直接看到unicode字节串,它会被显示为中文的“中文”;因为python3默认使用unicode编码,unicode字节串将被直接处理为中文显示出来。
获取字符的unicode
- 根据unicode获取字符
1 | # chr参数支持10进制、16进制 |
- 根据字符获取unicode码
1 | # 返回值:10进制的unicode码 |
Python2中的print过程
Python2.7中调用print打印var变量时,操作系统会对var做一定的字符处理:
- 如果
var是str类型的变量,则直接将var变量交付给终端进行显示; - 如果
var变量是unicode类型,则操作系统首先将var编码成str类型的对象(编码格式取决于stdout的编码格式print(sys.stdout.encoding)),然后再交由终端进行显示。 - 在终端显示时,如果str类型的变量的编码方式和终端设置的编码方式不一致,很可能会出现乱码问题。
Python2 与3 读取文件的编码问题
codecs会按照指定的字符集解码文件,然后将字符串转为<type 'unicode'>
open读取文件后的字符串是<type 'str'> 类型,而且a.txt是以utf8编码保存的,与‘分’是同一种编码(# _*_ coding:utf8 _*_),因此可以直接split
a.txt中的内容是:中文分国家
1 | # _*_ coding:utf8 _*_ |
python3中都是unicode存储字符串,因此没有上面的问题
1 | # python3 |